MyBatis 是一个半自动化的ORM框架
0.28. 、Xml 映射文件中,除了常见的 select|insert|update|delete 标签之外,还有哪些标签?
0.29. 、最佳实践中,通常一个 Xml 映射文件,都会写一个 Dao 接口与之对应,请问,这个 Dao 接口的工作原理是什么?Dao 接口里的方法,参数不同时,方法能重载吗?
0.42. 、MyBatis 映射文件中,如果 A 标签通过 include 引用了 B 标签的内容,请问,B 标签能否定义在 A 标签的后面,还是说必须定义在 A 标签的前面?
0.44. 、为什么说 MyBatis 是半自动 ORM 映射工具?它与全自动的区别在哪里?
MyBatis 是一个半自动化的ORM框架所有的增删改操作都需要提交事务!
接口所有的普通参数,尽量都写上@Param参数,尤其是多个参数时,必须写上!
有时候根据业务的需求,可以考虑使用map传递参数!
为了规范操作,在SQL的配置文件中,我们尽量将Parameter参数和resultType都写上!


Caching缓存
Simple
Batch批量
Reuse复用
http://www.mybatis.cn/category/interview/
maven静态资源过滤问题
<resources> |
0.1. MyBatis与Hibernate有哪些不同?
1、Mybatis和hibernate不同,它不完全是一个ORM框架,因为MyBatis需要程序员自己编写Sql语句。
2、Mybatis直接编写原生态sql,可以严格控制sql执行性能,灵活度高,非常适合对关系数据模型要求不高的软件开发,因为这类软件需求变化频繁,一但需求变化要求迅速输出成果。但是灵活的前提是mybatis无法做到数据库无关性,如果需要实现支持多种数据库的软件,则需要自定义多套sql映射文件,工作量大。
3、Hibernate对象/关系映射能力强,数据库无关性好,对于关系模型要求高的软件,如果用hibernate开发可以节省很多代码,提高效率。
0.2. 模糊查询like
第1种:在Java代码中添加sql通配符。
string wildcardname = “%smi%”; |
第2种:在sql语句中拼接通配符,会引起sql注入
string wildcardname = “smi”; |
或是利用sql的contact函数。
<select id="selectLike"> |
0.3. 引入资源方式
<!-- 使用相对于类路径的资源引用 --> |
0.4. namespace
namespace中文意思:命名空间,作用如下:
- namespace的命名必须跟某个接口同名
- 接口中的方法与映射文件中sql语句id应该一一对应
- namespace和子元素的id联合保证唯一 , 区别不同的mapper
- 绑定DAO接口
- namespace命名规则 : 包名+类名
0.5. Dao接口和XML文件里的SQL是如何建立关系的?
通过Dao接口生成的动态代理调用查询,根据绑定的namespace确定唯一id,在注册中心里找到mappedStatement,通过sqlSource生成SQL语句,jdbc执行返回。
0.5.1. 一、解析XML
首先,Mybatis在初始化SqlSessionFactoryBean的时候,找到mapperLocations路径去解析里面所有的XML文件,这里我们重点关注两部分。
0.5.1.1. 、创建SqlSource
Mybatis会把每个SQL标签封装成SqlSource对象,然后根据SQL语句的不同,又分为动态SQL和静态SQL。其中,静态SQL包含一段String类型的sql语句;而动态SQL则是由一个个SqlNode组成。
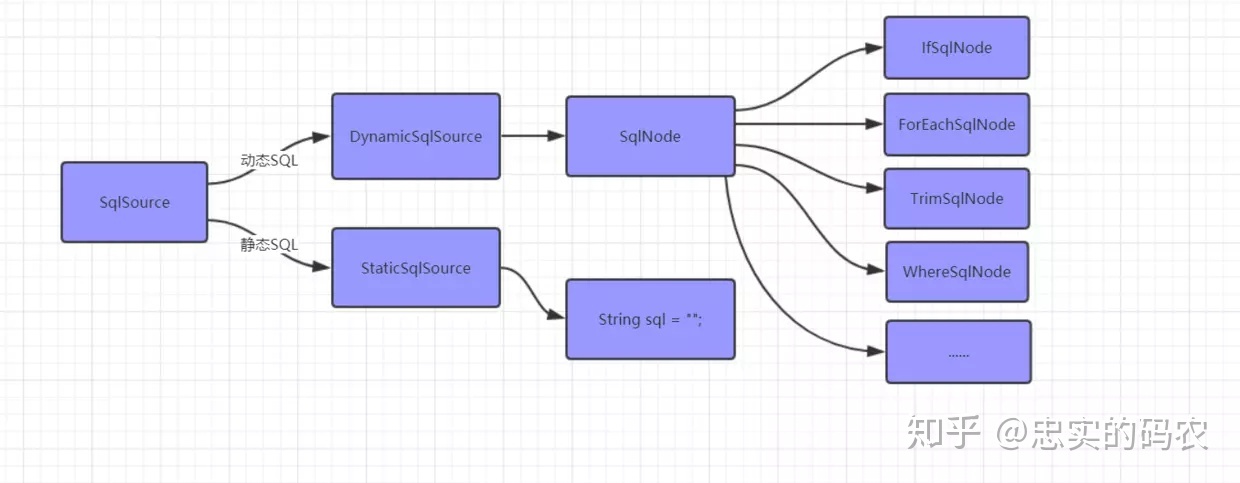
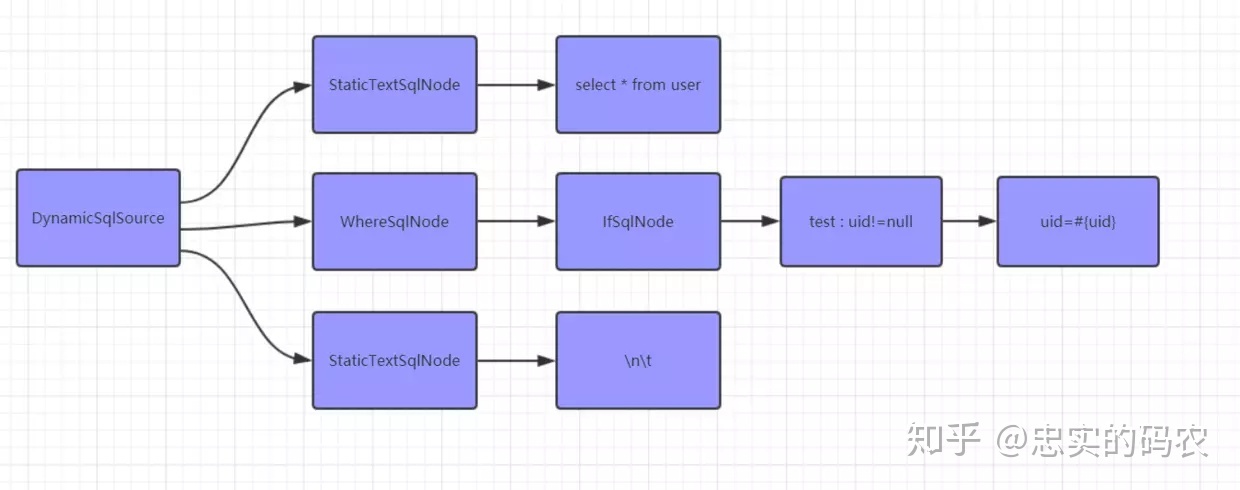
0.5.1.2. 、创建MappedStatement
XML文件中的每一个SQL标签就对应一个MappedStatement对象,这里面有两个属性很重要。
id:全限定类名+方法名组成的ID。
sqlSource:当前SQL标签对应的SqlSource对象。
创建完MappedStatement对象,将它缓存到Configuration#mappedStatements中。
Configuration对象就是Mybatis中的大管家,基本所有的配置信息都维护在这里。把所有的XML都解析完成之后,Configuration就包含了所有的SQL信息。
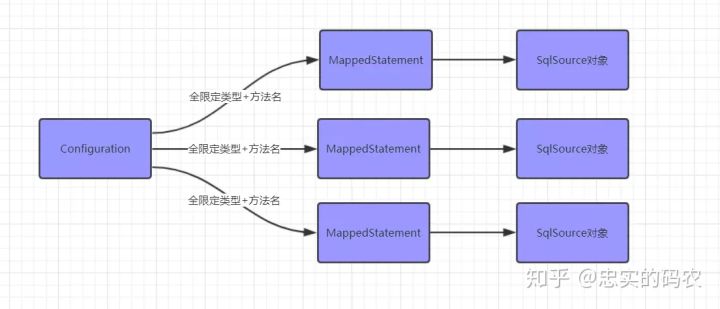
到目前为止,XML就解析完成了。当我们执行Mybatis方法的时候,就通过全限定类名+方法名找到MappedStatement对象,然后解析里面的SQL内容,执行即可。
0.5.2. 二、Dao接口代理
我们的Dao接口并没有实现类,那么,我们在调用它的时候,它是怎样最终执行到我们的SQL语句的呢?
首先,我们在Spring配置文件中,一般会这样配置:
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> |
或者你的项目是基于SpringBoot的,那么肯定也见过这种:
@MapperScan(“com.xxx.dao”)
它们的作用是一样的。将包路径下的所有类注册到Spring Bean中,并且将它们的beanClass设置为MapperFactoryBean。MapperFactoryBean实现了FactoryBean接口,俗称工厂Bean。那么,当我们通过@Autowired注入这个Dao接口的时候,返回的对象就是MapperFactoryBean这个工厂Bean中的getObject()方法对象。
简单来说,它就是通过JDK动态代理,返回了一个Dao接口的代理对象,这个代理对象的处理器是MapperProxy对象。所有,我们通过@Autowired注入Dao接口的时候,注入的就是这个代理对象,我们调用到Dao接口的方法时,则会调用到MapperProxy对象的invoke方法。
曾经有个朋友问过这样一个问题:
对于有实现的dao接口,mapper还会用代理么?
答案是肯定,只要你配置了MapperScan,它就会去扫描,然后生成代理。但是,如果你的dao接口有实现类,并且这个实现类也是一个Spring Bean,那就要看你在Autowired的时候,去注入哪一个了。
会报错,因为在注入的时候,找到了两个UserDao的实例对象。其实我们通过名字注入就可以了。
0.5.3. 三、执行
如上所述,当我们调用Dao接口方法的时候,实际调用到代理对象的invoke方法。 在这里,实际上调用的就是SqlSession里面的东西了。
public class DefaultSqlSession implements SqlSession { |
是通过statement全限定类型+方法名拿到MappedStatement 对象,然后通过执行器Executor去执行具体SQL并返回。
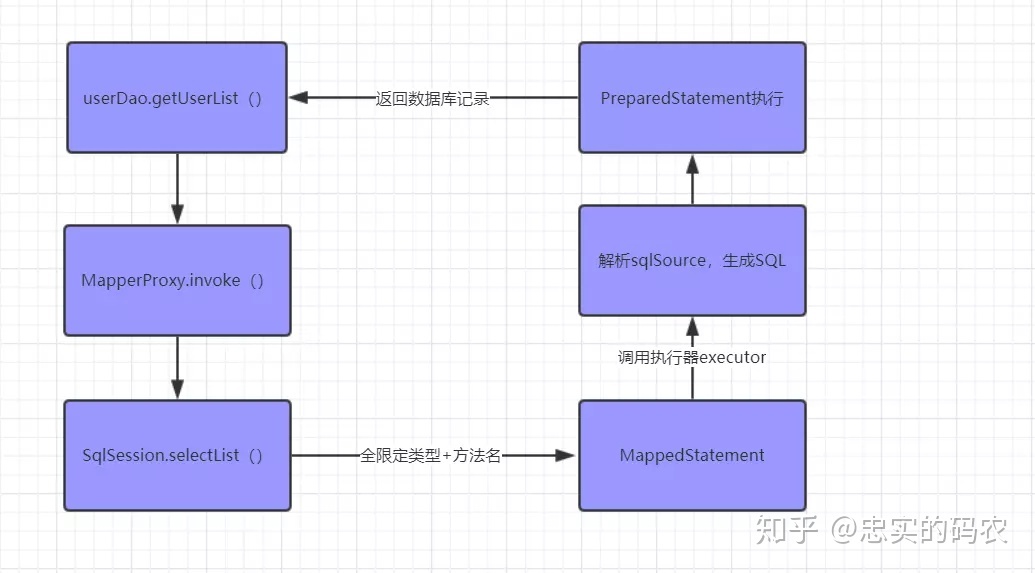
0.6. 作用域
作用域理解
- SqlSessionFactoryBuilder 的作用在于创建 SqlSessionFactory,创建成功后,SqlSessionFactoryBuilder 就失去了作用,所以它只能存在于创建 SqlSessionFactory 的方法中,而不要让其长期存在。因此 SqlSessionFactoryBuilder 实例的最佳作用域是方法作用域(也就是局部方法变量)。
- SqlSessionFactory 可以被认为是一个数据库连接池,它的作用是创建 SqlSession 接口对象。因为 MyBatis 的本质就是 Java 对数据库的操作,所以 SqlSessionFactory 的生命周期存在于整个 MyBatis 的应用之中,所以一旦创建了 SqlSessionFactory,就要长期保存它,直至不再使用 MyBatis 应用,所以可以认为 SqlSessionFactory 的生命周期就等同于 MyBatis 的应用周期。
- 由于 SqlSessionFactory 是一个对数据库的连接池,所以它占据着数据库的连接资源。如果创建多个 SqlSessionFactory,那么就存在多个数据库连接池,这样不利于对数据库资源的控制,也会导致数据库连接资源被消耗光,出现系统宕机等情况,所以尽量避免发生这样的情况。
- 因此在一般的应用中我们往往希望 SqlSessionFactory 作为一个单例,让它在应用中被共享。所以说 SqlSessionFactory 的最佳作用域是应用作用域。
- 如果说 SqlSessionFactory 相当于数据库连接池,那么 SqlSession 就相当于一个数据库连接(Connection 对象),你可以在一个事务里面执行多条 SQL,然后通过它的 commit、rollback 等方法,提交或者回滚事务。所以它应该存活在一个业务请求中,处理完整个请求后,应该关闭这条连接,让它归还给 SqlSessionFactory,否则数据库资源就很快被耗费精光,系统就会瘫痪,所以用 try…catch…finally… 语句来保证其正确关闭。
- 所以 SqlSession 的最佳的作用域是请求或方法作用域。
0.7. 属性名和字段名不一致
方案一:为列名指定别名 , 别名和java实体类的属性名一致 .
<select id="selectUserById" resultType="User"> |
方案二:使用结果集映射->ResultMap 【推荐】
<resultMap id="UserMap" type="User"> |
0.8. ResultMap
自动映射
简单地将所有的列映射到 HashMap 的键上,这由 resultType 属性指定。虽然在大部分情况下都够用,但是 HashMap 不是一个很好的模型。你的程序更可能会使用 JavaBean 或 POJO(Plain Old Java Objects,普通老式 Java 对象)作为模型。
手动映射
返回值类型为resultMap
0.9. 分页
limit物理分页
#语法 |
RowBounds逻辑分页
除了使用Limit在SQL层面实现分页,也可以使用RowBounds在Java代码层面实现分页
SqlSession session = MybatisUtils.getSession(); |
PageHelper
0.10. 在mapper中如何传递多个参数?
1、第一种:
DAO层的函数
2、第二种: 使用 @param 注解:
然后,就可以在xml像下面这样使用(推荐封装为一个map,作为单个参数传递给mapper):
3、第三种:多个参数封装成map
0.11. Mapper 编写有哪几种方式?
接口实现类继承 SqlSessionDaoSupport:使用此种方法需要编写mapper 接口,mapper 接口实现类、mapper.xml 文件
1、在 sqlMapConfig.xml 中配置 mapper.xml 的位置
<mappers> |
2、定义 mapper 接口
3、实现类集成 SqlSessionDaoSupport,mapper 方法中可以 this.getSqlSession()进行数据增删改查。
4、spring 配置
<bean id=" " class="mapper 接口的实现"> |
- 使用 org.mybatis.spring.mapper.MapperFactoryBean :
1、在 sqlMapConfig.xml 中配置 mapper.xml 的位置,如果 mapper.xml 和 mappre 接口的名称相同且在同一个目录,这里可以不用配置
<mapper resource="mapper.xml 文件的地址" /> |
2、定义 mapper 接口:
2.1、mapper.xml 中的 namespace 为 mapper 接口的地址
2.2、mapper 接口中的方法名和 mapper.xml 中的定义的 statement 的 id 保持一 致
3、Spring 中定义
使用 mapper 扫描器:
1、mapper.xml 文件编写:
mapper.xml 中的 namespace 为 mapper 接口的地址;
mapper 接口中的方法名和 mapper.xml 中的定义的 statement 的 id 保持一致;
如果将 mapper.xml 和 mapper 接口的名称保持一致则不用在 sqlMapConfig.xml 中进行配置2、定义 mapper 接口:
注意 mapper.xml 的文件名和 mapper 的接口名称保持一致,且放在同一个目录3、配置 mapper 扫描器:
<bean class="org.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="mapper 接口包地址"></property>
<property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"/>
</bean>4、使用扫描器后从 spring 容器中获取 mapper 的实现对象。
0.12. 注解
1、我们在我们的接口中添加注解
//查询全部用户 |
2、在mybatis的核心配置文件中注入
<!--使用class绑定接口--> |
0.13. Mybatis详细的执行流程
0.14. MyBatis的工作原理以及核心流程介绍
JDBC有四个核心对象:
(1)DriverManager,用于注册数据库连接
(2)Connection,与数据库连接对象
(3)Statement/PrepareStatement,操作数据库SQL语句的对象
(4)ResultSet,结果集或一张虚拟表MyBatis也有四大核心对象:
(1)SqlSession对象,该对象中包含了执行SQL语句的所有方法。类似于JDBC里面的Connection
(2)Executor接口,它将根据SqlSession传递的参数动态地生成需要执行的SQL语句,同时负责查询缓存的维护。类似于JDBC里面的Statement/PrepareStatement。
(3)MappedStatement对象,该对象是对映射SQL的封装,用于存储要映射的SQL语句的id、参数等信息。
(4)ResultHandler对象,用于对返回的结果进行处理,最终得到自己想要的数据格式或类型。可以自定义返回类型。
0.14.1. 、MyBatis的工作原理以及核心流程详解
MyBatis的工作原理如下图所示:
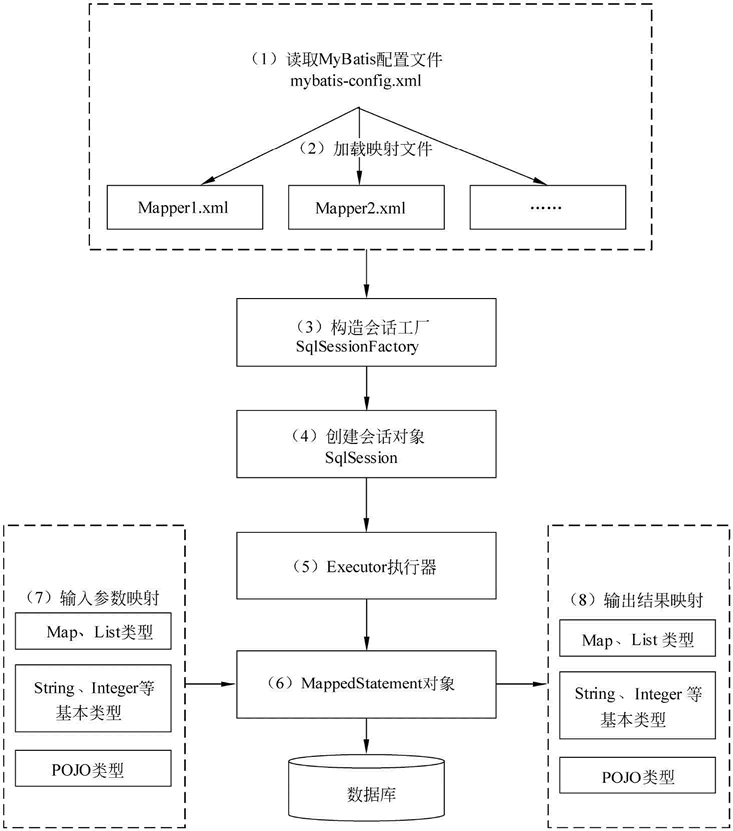
(1)读取MyBatis的配置文件。mybatis-config.xml为MyBatis的全局配置文件,用于配置数据库连接信息。
(2)加载映射文件。映射文件即SQL映射文件,该文件中配置了操作数据库的SQL语句,需要在MyBatis配置文件mybatis-config.xml中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表。
(3)构造会话工厂。通过MyBatis的环境配置信息构建会话工厂SqlSessionFactory。
(4)创建会话对象。由会话工厂创建SqlSession对象,该对象中包含了执行SQL语句的所有方法。
(5)Executor执行器。MyBatis底层定义了一个Executor接口来操作数据库,它将根据SqlSession传递的参数动态地生成需要执行的SQL语句,同时负责查询缓存的维护。
(6)MappedStatement对象。在Executor接口的执行方法中有一个MappedStatement类型的参数,该参数是对映射信息的封装,用于存储要映射的SQL语句的id、参数等信息。
(7)输入参数映射。输入参数类型可以是Map、List等集合类型,也可以是基本数据类型和POJO类型。输入参数映射过程类似于JDBC对preparedStatement对象设置参数的过程。
(8)输出结果映射。输出结果类型可以是Map、List等集合类型,也可以是基本数据类型和POJO类型。输出结果映射过程类似于JDBC对结果集的解析过程。
0.15. @Param
@Param注解用于给方法参数起一个名字。以下是总结的使用原则:
在方法只接受一个参数的情况下,可以不使用@Param。
在方法接受多个参数的情况下,建议一定要使用@Param注解给参数命名。
如果参数是 JavaBean , 则不能使用@Param。
不使用@Param注解时,参数只能有一个,并且是Javabean。
0.16. #与$的区别
/#{} 的作用主要是替换预编译语句(PrepareStatement)中的占位符? 【推荐使用】
INSERT INTO user (name) VALUES (#{name}); |
${} 的作用是直接进行字符串替换
INSERT INTO user (name) VALUES ('${name}'); |
(3)使用#{}可以有效的防止SQL注入,提高系统安全性。原因在于:预编译机制。预编译完成之后,SQL的结构已经固定,即便用户输入非法参数,也不会对SQL的结构产生影响,从而避免了潜在的安全风险。
(4)预编译是提前对SQL语句进行预编译,而其后注入的参数将不会再进行SQL编译。我们知道,SQL注入是发生在编译的过程中,因为恶意注入了某些特殊字符,最后被编译成了恶意的执行操作。而预编译机制则可以很好的防止SQL注入。
0.17. 数据库链接中断如何处理
数据库的访问底层是通过tcp实现的,如果数据库链接中断,那么应用程序是不知道的,跟时间有关的设置有:max_idle_time,connect_timeout。max_idle_time表明最大的空闲时间,超过这个时间socket就会关闭,timeout。
0.18. 数据库插入重复如何处理
插入的过程一般都是分两步的:先判断是否存在记录,没有存在则插入否则不插入。如果存在并发操作,那么同时进行了第一步,然后大家都发现没有记录,最后在第二步的时候都插入了数据从而造成数据的重复。解决插入重复的思路可以是这样的:
下面场景,假设同时有三个线程:线程a、线程b、线程c,进行插入操作。
(1)判断数据库是否有数据,有的话则无所作为。没有数据的话,则进行下面第2步。
(2)大家都要去竞争锁,用redis当锁,即:redis set key,其中只有一个操作a会成功,其他并发的线程b和c会失败的。
(3)上面set key 成功的线程a,开始执行插入数据操作,无论是否插入数据成功,都在最后del key。【注】插入不成功可以多尝试几次,增加成功的概率。
(4)如果拿到锁的线程a没有插入成功,即便是尝试了数次也没有插入成功,此时定是系统出现了bug,应该搞一个短信报警机制,让研发人员及时发现问题。
0.19. 一个Connection在MySQL中对应一个线程?
在高性能服务器端端开发底层往往靠io复用来处理,这种模式就是:单线程+事件处理机制。在MySQL里面往往有一个主线程,这是单线程(与Java中处处强调多线程的思想有点不同哦),它不断的循环查看是否有socket是否有读写事件,如果有读写事件,再从线程池里面找个工作线程处理这个socket的读写事件,完事之后工作线程会回到线程池。所以:Java客户端中的一个Connection不是在MySQL中就对应一个线程来处理这个链接,而是由监听socket的主线程+线程池里面固定数目的工作线程来处理的。
0.20. 预编译的过程
0.20.1. 、JDBC的预编译用法
相信每个人都应该了解JDBC中的PreparedStatement接口,它是用来实现SQL预编译的功能。其用法是这样的:
Class.forName("com.mysql.jdbc.Driver"); |
0.20.2. 、预编译的好处
0.20.2.1. 、预编译能避免SQL注入
预编译功能可以避免SQL注入,因为SQL已经编译完成,其结构已经固定,用户的输入只能当做参数传入进去,不能再破坏SQL的结果,无法造成曲解SQL原本意思的破坏。
0.20.2.2. 、预编译能提高SQL执行效率
预编译功能除了避免SQL注入,还能提高SQL执行效率。当客户发送一条SQL语句给服务器后,服务器首先需要校验SQL语句的语法格式是否正确,然后把SQL语句编译成可执行的函数,最后才是执行SQL语句。其中校验语法,和编译所花的时间可能比执行SQL语句花的时间还要多。
如果我们需要执行多次insert语句,但只是每次插入的值不同,MySQL服务器也是需要每次都去校验SQL语句的语法格式以及编译,这就浪费了太多的时间。如果使用预编译功能,那么只对SQL语句进行一次语法校验和编译,所以效率要高。
0.20.3. 、预编译的实现过程
预编译功能如此重要,那么数据库是如何实现预编译的呢?这个问题其实可以当做一个面试题,能很好的考察面试者对预编译的理解。下面以MySQL为例说明一下预编译的过程:
MySQL执行预编译分为如三步:
第一步:执行预编译语句,例如:prepare myperson from ‘select * from t_person where name=?’
第二步:设置变量,例如:set @name=’Jim’
第三步:执行语句,例如:execute myperson using @name
如果需要再次执行myperson,那么就不再需要第一步,即不需要再编译语句了:
设置变量,例如:set @name=’Tom’
执行语句,例如:execute myperson using @name
0.21.
0.22. 多对一
多对一的理解:
- 多个学生对应一个老师
- 如果对于学生这边,就是一个多对一的现象,即从学生这边关联一个老师!
0.22.1. 按查询嵌套处理
1、给StudentMapper接口增加方法
//获取所有学生及对应老师的信息 |
2、编写对应的Mapper文件
|
3、编写完毕去Mybatis配置文件中,注册Mapper!
4、注意点说明:
<resultMap id="StudentTeacher" type="Student"> |
0.22.2. 按结果嵌套处理
1、接口方法编写
public List<Student> getStudents2(); |
2、编写对应的mapper文件
<!-- |
0.23. 一对多
对多的理解:
- 一个老师拥有多个学生
- 如果对于老师这边,就是一个一对多的现象,即从一个老师下面拥有一群学生(集合)!
0.23.1. 按结果嵌套处理
1、TeacherMapper接口编写方法
//获取指定老师,及老师下的所有学生 |
2、编写接口对应的Mapper配置文件
<mapper namespace="com.kuang.mapper.TeacherMapper"> |
0.23.2. 按查询嵌套处理
1、TeacherMapper接口编写方法
public Teacher getTeacher2(int id); |
2、编写接口对应的Mapper配置文件
<select id="getTeacher2" resultMap="TeacherStudent2"> |
小结
1、关联-association
2、集合-collection
3、所以association是用于一对一和多对一,而collection是用于一对多的关系
4、JavaType和ofType都是用来指定对象类型的
- JavaType是用来指定pojo中属性的类型
- ofType指定的是映射到list集合属性中pojo的类型。
0.24. 动态 SQL
动态SQL指的是根据不同的查询条件 , 生成不同的Sql语句.
------------------------------- |
0.25. Dao接口的工作原理
Dao接口即Mapper接口。接口的全限名,就是映射文件中的namespace的值;接口的方法名,就是映射文件中Mapper的Statement的id值;接口方法内的参数,就是传递给sql的参数。
Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MapperStatement。在Mybatis中,每一个
举例来说:cn.mybatis.mappers.StudentDao.findStudentById,可以唯一找到namespace为 com.mybatis.mappers.StudentDao下面 id 为 findStudentById 的 MapperStatement。
Mapper接口里的方法,是不能重载的,因为是使用 全限名+方法名 的保存和寻找策略。Mapper 接口的工作原理是JDK动态代理,Mybatis运行时会使用JDK动态代理为Mapper接口生成代理对象proxy,代理对象会拦截接口方法,转而执行MapperStatement所代表的sql,然后将sql执行结果返回。
0.26. 缓存
1、什么是缓存 [ Cache ]?
- 存在内存中的临时数据。
- 将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题。
2、为什么使用缓存?
- 减少和数据库的交互次数,减少系统开销,提高系统效率。
3、什么样的数据能使用缓存?
- 经常查询并且不经常改变的数据。
Mybatis的缓存实际上就是一个HashMap,key是真正执行的sql语句,value是缓存的结果。
0.26.1. 一级缓存
一级缓存也叫本地缓存:
- 与数据库同一次会话期间查询到的数据会放在本地缓存中。
- 以后如果需要获取相同的数据,直接从缓存中拿,没必须再去查询数据库;
一级缓存失效的四种情况:
一级缓存是SqlSession级别的缓存,是一直开启的,我们关闭不了它;
一级缓存失效情况:没有使用到当前的一级缓存,效果就是,还需要再向数据库中发起一次查询请求!
1、sqlSession不同。每个sqlSession中的缓存相互独立
2、sqlSession相同,查询条件不同。当前缓存中,不存在这个数据
3、sqlSession相同,两次查询之间执行了增删改操作!因为增删改操作可能会对当前数据产生影响
4、sqlSession相同,手动清除一级缓存。session.clearCache();
0.26.2. 二级缓存
二级缓存也叫全局缓存,一级缓存作用域太低了,所以诞生了二级缓存
基于namespace级别的缓存,一个名称空间,对应一个二级缓存;
工作机制
- 一个会话查询一条数据,这个数据就会被放在当前会话的一级缓存中;
- 如果当前会话关闭了,这个会话对应的一级缓存就没了;但是我们想要的是,会话关闭了,一级缓存中的数据被保存到二级缓存中;
- 新的会话查询信息,就可以从二级缓存中获取内容;
- 不同的mapper查出的数据会放在自己对应的缓存(map)中;
总结
- 只要开启了二级缓存,我们在同一个Mapper中的查询,可以在二级缓存中拿到数据
- 查出的数据都会被默认先放在一级缓存中
- 只有会话提交或者关闭以后,一级缓存中的数据才会转到二级缓存中
- 查询时顺序:二级 -> 一级 -> 数据库
- 对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear。
0.27. 、#{}和${}的区别是什么?
注:这道题是面试官面试我同事的。
答:
${}是 Properties 文件中的变量占位符,它可以用于标签属性值和 sql 内部,属于静态文本替换,比如${driver}会被静态替换为com.mysql.jdbc.Driver。#{}是 sql 的参数占位符,MyBatis 会将 sql 中的#{}替换为?号,在 sql 执行前会使用 PreparedStatement 的参数设置方法,按序给 sql 的?号占位符设置参数值,比如 ps.setInt(0, parameterValue),#{item.name}的取值方式为使用反射从参数对象中获取 item 对象的 name 属性值,相当于param.getItem().getName()。
0.28. 、Xml 映射文件中,除了常见的 select|insert|update|delete 标签之外,还有哪些标签?
注:这道题是京东面试官面试我时问的。
答:还有很多其他的标签,<resultMap>、<parameterMap>、<sql>、<include>、<selectKey>,加上动态 sql 的 9 个标签,trim|where|set|foreach|if|choose|when|otherwise|bind等,其中<include>标签引入 sql 片段,<selectKey>为不支持自增的主键生成策略标签。
0.29. 、最佳实践中,通常一个 Xml 映射文件,都会写一个 Dao 接口与之对应,请问,这个 Dao 接口的工作原理是什么?Dao 接口里的方法,参数不同时,方法能重载吗?
注:这道题也是京东面试官面试我被问的。
答:Dao 接口,就是人们常说的 Mapper接口,接口的全限名,就是映射文件中的 namespace 的值,接口的方法名,就是映射文件中MappedStatement的 id 值,接口方法内的参数,就是传递给 sql 的参数。Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为 key 值,可唯一定位一个MappedStatement,举例:com.mybatis3.mappers.StudentDao.findStudentById,可以唯一找到 namespace 为com.mybatis3.mappers.StudentDao下面id = findStudentById的MappedStatement。在 MyBatis 中,每一个<select>、<insert>、<update>、<delete>标签,都会被解析为一个MappedStatement对象。
Dao 接口里的方法,是不能重载的,因为是全限名+方法名的保存和寻找策略。
Dao 接口里的方法可以重载,但是Mybatis的XML里面的ID不允许重复。
Mybatis版本3.3.0,亲测如下:
/** * Mapper接口里面方法重载 */public interface StuMapper { List<Student> getAllStu(); List<Student> getAllStu( Integer id);} |
然后在 StuMapper.xml 中利用Mybatis的动态sql就可以实现。
<select id="getAllStu" resultType="com.pojo.Student"> select * from student <where> <if test="id != null"> id = #{id} </if> </where> </select> |
能正常运行,并能得到相应的结果,这样就实现了在Dao接口中写重载方法。
Mybatis 的 Dao 接口可以有多个重载方法,但是多个接口对应的映射必须只有一个,否则启动会报错。
相关 issue :更正:Dao 接口里的方法可以重载,但是Mybatis的XML里面的ID不允许重复!。
Dao 接口的工作原理是 JDK 动态代理,MyBatis 运行时会使用 JDK 动态代理为 Dao 接口生成代理 proxy 对象,代理对象 proxy 会拦截接口方法,转而执行MappedStatement所代表的 sql,然后将 sql 执行结果返回。
0.29.1. ==补充:==
Dao接口方法可以重载,但是需要满足以下条件:
- 仅有一个无参方法和一个有参方法
- 多个有参方法时,参数数量必须一致。且使用相同的
@Param,或者使用param1这种
测试如下:
PersonDao.java
Person queryById();Person queryById( Long id);Person queryById( Long id, String name); |
PersonMapper.xml
<select id="queryById" resultMap="PersonMap"> select id, name, age, address from person <where> <if test="id != null"> id = #{id} </if> <if test="name != null and name != ''"> name = #{name} </if> </where> limit 1</select> |
org.apache.ibatis.scripting.xmltags.DynamicContext.ContextAccessor#getProperty方法用于获取<if>标签中的条件值
public Object getProperty(Map context, Object target, Object name) { Map map = (Map) target; Object result = map.get(name); if (map.containsKey(name) || result != null) { return result; } Object parameterObject = map.get(PARAMETER_OBJECT_KEY); if (parameterObject instanceof Map) { return ((Map)parameterObject).get(name); } return null;} |
parameterObject为map,存放的是Dao接口中参数相关信息。
((Map)parameterObject).get(name)方法如下
public V get(Object key) { if (!super.containsKey(key)) { throw new BindingException("Parameter '" + key + "' not found. Available parameters are " + keySet()); } return super.get(key);} |
queryById()方法执行时,parameterObject为null,getProperty方法返回null值,<if>标签获取的所有条件值都为null,所有条件不成立,动态sql可以正常执行。queryById(1L)方法执行时,parameterObject为map,包含了id和param1两个key值。当获取<if>标签中name的属性值时,进入((Map)parameterObject).get(name)方法中,map中key不包含name,所以抛出异常。queryById(1L,"1")方法执行时,parameterObject中包含id,param1,name,param2四个key值,id和name属性都可以获取到,动态sql正常执行。
0.30. 、MyBatis 是如何进行分页的?分页插件的原理是什么?
注:我出的。
答:**(1)** MyBatis 使用 RowBounds 对象进行分页,它是针对 ResultSet 结果集执行的内存分页,而非物理分页;**(2)** 可以在 sql 内直接书写带有物理分页的参数来完成物理分页功能,**(3)** 也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用 MyBatis 提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的 sql,然后重写 sql,根据 dialect 方言,添加对应的物理分页语句和物理分页参数。
举例:select _ from student,拦截 sql 后重写为:select t._ from (select \* from student)t limit 0,10
0.31. 、简述 MyBatis 的插件运行原理,以及如何编写一个插件。
注:我出的。
答:MyBatis 仅可以编写针对 ParameterHandler、ResultSetHandler、StatementHandler、Executor 这 4 种接口的插件,MyBatis 使用 JDK 的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这 4 种接口对象的方法时,就会进入拦截方法,具体就是 InvocationHandler 的 invoke()方法,当然,只会拦截那些你指定需要拦截的方法。
实现 MyBatis 的 Interceptor 接口并复写 intercept()方法,然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可,记住,别忘了在配置文件中配置你编写的插件。
0.32. 、MyBatis 执行批量插入,能返回数据库主键列表吗?
注:我出的。
答:能,JDBC 都能,MyBatis 当然也能。
0.33. 、MyBatis 动态 sql 是做什么的?都有哪些动态 sql?能简述一下动态 sql 的执行原理不?
注:我出的。
答:MyBatis 动态 sql 可以让我们在 Xml 映射文件内,以标签的形式编写动态 sql,完成逻辑判断和动态拼接 sql 的功能,MyBatis 提供了 9 种动态 sql 标签 trim|where|set|foreach|if|choose|when|otherwise|bind。
其执行原理为,使用 OGNL 从 sql 参数对象中计算表达式的值,根据表达式的值动态拼接 sql,以此来完成动态 sql 的功能。
0.34. 、MyBatis 是如何将 sql 执行结果封装为目标对象并返回的?都有哪些映射形式?
注:我出的。
答:第一种是使用<resultMap>标签,逐一定义列名和对象属性名之间的映射关系。第二种是使用 sql 列的别名功能,将列别名书写为对象属性名,比如 T_NAME AS NAME,对象属性名一般是 name,小写,但是列名不区分大小写,MyBatis 会忽略列名大小写,智能找到与之对应对象属性名,你甚至可以写成 T_NAME AS NaMe,MyBatis 一样可以正常工作。
有了列名与属性名的映射关系后,MyBatis 通过反射创建对象,同时使用反射给对象的属性逐一赋值并返回,那些找不到映射关系的属性,是无法完成赋值的。
0.35. 、MyBatis 能执行一对一、一对多的关联查询吗?都有哪些实现方式,以及它们之间的区别。
注:我出的。
答:能,MyBatis 不仅可以执行一对一、一对多的关联查询,还可以执行多对一,多对多的关联查询,多对一查询,其实就是一对一查询,只需要把 selectOne()修改为 selectList()即可;多对多查询,其实就是一对多查询,只需要把 selectOne()修改为 selectList()即可。
关联对象查询,有两种实现方式,一种是单独发送一个 sql 去查询关联对象,赋给主对象,然后返回主对象。另一种是使用嵌套查询,嵌套查询的含义为使用 join 查询,一部分列是 A 对象的属性值,另外一部分列是关联对象 B 的属性值,好处是只发一个 sql 查询,就可以把主对象和其关联对象查出来。
那么问题来了,join 查询出来 100 条记录,如何确定主对象是 5 个,而不是 100 个?其去重复的原理是<resultMap>标签内的<id>子标签,指定了唯一确定一条记录的 id 列,MyBatis 根据<id>可以有多个,代表了联合主键的语意。
同样主对象的关联对象,也是根据这个原理去重复的,尽管一般情况下,只有主对象会有重复记录,关联对象一般不会重复。
举例:下面 join 查询出来 6 条记录,一、二列是 Teacher 对象列,第三列为 Student 对象列,MyBatis 去重复处理后,结果为 1 个老师 6 个学生,而不是 6 个老师 6 个学生。
| t_id | t_name | s_id |
|---|---|---|
| 1 | teacher | 38 |
| 1 | teacher | 39 |
| 1 | teacher | 40 |
| 1 | teacher | 41 |
| 1 | teacher | 42 |
| 1 | teacher | 43 |
0.36. 、MyBatis 是否支持延迟加载?如果支持,它的实现原理是什么?
注:我出的。
答:MyBatis 仅支持 association 关联对象和 collection 关联集合对象的延迟加载,association 指的就是一对一,collection 指的就是一对多查询。在 MyBatis 配置文件中,可以配置是否启用延迟加载 lazyLoadingEnabled=true|false。
它的原理是,使用 CGLIB 创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用 a.getB().getName(),拦截器 invoke()方法发现 a.getB()是 null 值,那么就会单独发送事先保存好的查询关联 B 对象的 sql,把 B 查询上来,然后调用 a.setB(b),于是 a 的对象 b 属性就有值了,接着完成 a.getB().getName()方法的调用。这就是延迟加载的基本原理。
当然了,不光是 MyBatis,几乎所有的包括 Hibernate,支持延迟加载的原理都是一样的。
0.37. 、MyBatis 的 Xml 映射文件中,不同的 Xml 映射文件,id 是否可以重复?
注:我出的。
答:不同的 Xml 映射文件,如果配置了 namespace,那么 id 可以重复;如果没有配置 namespace,那么 id 不能重复;毕竟 namespace 不是必须的,只是最佳实践而已。
原因就是 namespace+id 是作为 Map<String, MappedStatement>的 key 使用的,如果没有 namespace,就剩下 id,那么,id 重复会导致数据互相覆盖。有了 namespace,自然 id 就可以重复,namespace 不同,namespace+id 自然也就不同。
0.38. 、MyBatis 中如何执行批处理?
注:我出的。
答:使用 BatchExecutor 完成批处理。
0.39. 、MyBatis 都有哪些 Executor 执行器?它们之间的区别是什么?
注:我出的
答:MyBatis 有三种基本的 Executor 执行器,**SimpleExecutor、ReuseExecutor、BatchExecutor。**
SimpleExecutor:每执行一次 update 或 select,就开启一个 Statement 对象,用完立刻关闭 Statement 对象。
ReuseExecutor:执行 update 或 select,以 sql 作为 key 查找 Statement 对象,存在就使用,不存在就创建,用完后,不关闭 Statement 对象,而是放置于 Map<String, Statement>内,供下一次使用。简言之,就是重复使用 Statement 对象。
BatchExecutor:执行 update(没有 select,JDBC 批处理不支持 select),将所有 sql 都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个 Statement 对象,每个 Statement 对象都是 addBatch()完毕后,等待逐一执行 executeBatch()批处理。与 JDBC 批处理相同。
作用范围:Executor 的这些特点,都严格限制在 SqlSession 生命周期范围内。
0.40. 、MyBatis 中如何指定使用哪一种 Executor 执行器?
注:我出的
答:在 MyBatis 配置文件中,可以指定默认的 ExecutorType 执行器类型,也可以手动给 DefaultSqlSessionFactory 的创建 SqlSession 的方法传递 ExecutorType 类型参数。
0.41. 、MyBatis 是否可以映射 Enum 枚举类?
注:我出的
答:MyBatis 可以映射枚举类,不单可以映射枚举类,MyBatis 可以映射任何对象到表的一列上。映射方式为自定义一个 TypeHandler,实现 TypeHandler 的 setParameter()和 getResult()接口方法。TypeHandler 有两个作用,一是完成从 javaType 至 jdbcType 的转换,二是完成 jdbcType 至 javaType 的转换,体现为 setParameter()和 getResult()两个方法,分别代表设置 sql 问号占位符参数和获取列查询结果。
0.42. 、MyBatis 映射文件中,如果 A 标签通过 include 引用了 B 标签的内容,请问,B 标签能否定义在 A 标签的后面,还是说必须定义在 A 标签的前面?
注:我出的
答:虽然 MyBatis 解析 Xml 映射文件是按照顺序解析的,但是,被引用的 B 标签依然可以定义在任何地方,MyBatis 都可以正确识别。
原理是,MyBatis 解析 A 标签,发现 A 标签引用了 B 标签,但是 B 标签尚未解析到,尚不存在,此时,MyBatis 会将 A 标签标记为未解析状态,然后继续解析余下的标签,包含 B 标签,待所有标签解析完毕,MyBatis 会重新解析那些被标记为未解析的标签,此时再解析 A 标签时,B 标签已经存在,A 标签也就可以正常解析完成了。
0.43. 、简述 MyBatis 的 Xml 映射文件和 MyBatis 内部数据结构之间的映射关系?
注:我出的
答:MyBatis 将所有 Xml 配置信息都封装到 All-In-One 重量级对象 Configuration 内部。在 Xml 映射文件中,<parameterMap>标签会被解析为 ParameterMap 对象,其每个子元素会被解析为 ParameterMapping 对象。<resultMap>标签会被解析为 ResultMap 对象,其每个子元素会被解析为 ResultMapping 对象。每一个<select>、<insert>、<update>、<delete>标签均会被解析为 MappedStatement 对象,标签内的 sql 会被解析为 BoundSql 对象。
0.44. 、为什么说 MyBatis 是半自动 ORM 映射工具?它与全自动的区别在哪里?
注:我出的
答:Hibernate 属于全自动 ORM 映射工具,使用 Hibernate 查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全自动的。而 MyBatis 在查询关联对象或关联集合对象时,需要手动编写 sql 来完成,所以,称之为半自动 ORM 映射工具。
面试题看似都很简单,但是想要能正确回答上来,必定是研究过源码且深入的人,而不是仅会使用的人或者用的很熟的人,以上所有面试题及其答案所涉及的内容,在我的 MyBatis 系列博客中都有详细讲解和原理分析。